Can you run DeepSeek R1 on a 2009 Mac Pro?
Some people call it the cheese grader. Others call it the trashcan Mac (although that's a more apt description for the 2013 model). I simply call it my computer.

I have some other computers besides the Aluminum Tower, including an old ThinkPad, a newer, beefier ThinkPad that is my daily driver, and a Steam Deck. But, the now 16 year-old Silver Sentinel is my only desktop computer. I've been planning to get a new desktop for a while, but it's hard to justify dropping a few grand as a graduate student when I don't really do much gaming, and I already have both a Steam Deck and a Nintendo Switch that feel underused. So, it remains.
Anyway, here are the specs of the Silver Slab:
- CPU: 3.33 GHz 6-Core Intel Xeon
- Memory: 32 GB 1333 MHz DDR3
- Storage: 640 GB SATA Disk (plus a 500 GB disk, only used for backups)
- Graphics: AMD Radeon HD 7950 3 GB
- macOS version: 10.15.7
As you can tell, some hardware components have been upgraded over time, although some have not. Also, I am using a patch to be able to run macOS Catalina. There is a more recent project which can run even more recent versions of macOS on hardware as old as mine, but I am not using it as of yet. While the project looks excellent, I don't really expect that trying to run the latest version of macOS on hardware as old as mine is going to be particularly stable.
Besides, plenty of software can run on Catalina. While Homebrew is no longer officially supported, it seems to continue to work. I've played lots of Minecraft, Civilization V and VI, and Cube 2: Sauerbraten on my Tower of Power. I haven't tried it recently, but League of Legends plays fine too, as has JetBrain's IDEs, Eclipse, Firefox, and uhhh, Gimp. Discord also still works, even if my version is no longer officially supported. But I know what you're wondering: what about the cutting-edge, hyped-up applications of tomorrow? More specifically, can the 2009 Mac Pro run a state of the art reasoning large language model?
Probably not, right? But, I was going to give it a shot. I started one of the first tutorials online; the first step was to install Ollama, which is basically something between a package manager and a runtime environment for LLMs [1]. After pressing download, I immediately discovered Ollama was not supported for my version of macOS.
Still, I decided to download it anyway. The installation launcher required admin permission. What could go wrong?
It seemed to install just fine. I proceeded to check the version:
xbony2@xbony2s-Mac-Pro ~ % ollama -v
ollama version is 0.5.7Well, that seemed to be fine. From there, I moved onto the next step of the tutorial: downloading the model.
xbony2@xbony2s-Mac-Pro ~ % ollama run deepseek-r1
pulling manifest
pulling 96c415656d37... 100% ▕████████████████▏ 4.7 GB
pulling 369ca498f347... 100% ▕████████████████▏ 387 B
pulling 6e4c38e1172f... 100% ▕████████████████▏ 1.1 KB
pulling f4d24e9138dd... 100% ▕████████████████▏ 148 B
pulling 40fb844194b2... 100% ▕████████████████▏ 487 B
verifying sha256 digest
writing manifest
successPer default, this is the 7B parameter model. The tutorial suggested using deepseek-r1:1.5b on "environments with limited computational resources". Obviously, I'm not a baby, so I went with the default.
I was initially concerned about having enough storage, but it turns out that the default model was less than 5 GB, which is astoundingly small. If the model is indeed capable of a broad array of tasks, it is truly an impressive engineering feat. In comparison, the size of the English Wikipedia is about 24 GB, without media and after compression.
Anyway, it downloaded fine, and then a prompt appeared. Still not expecting much, I entered the more basic question I could think of:
>>> What is your name?<think>
Alright, so I just came across this question: "What is your name?" At
first glance, it seems pretty straightforward. But wait, the user
mentioned that they're an AI assistant from DeepSeek and can help with
various tasks like answering questions, providing explanations, and
offering suggestions. Hmm, interesting.
Okay, let me break this down step by step. First, I need to understand
exactly what's being asked here. The question is pretty simple—just asking
for my name. But since the user already knows they're an AI assistant from
DeepSeek, maybe that's part of their identity or something? So perhaps the
answer should reflect that.
But wait, when someone asks "What is your name?", are they trying to test
if I'm aware of my own identity, or is it a general question? In this
context, since the user has already provided information about themselves,
maybe it's just a way to confirm their identity. So, responding with my
name being DeepSeek AI Assistant makes sense.
However, sometimes people ask for your name as part of a different
process, like when setting up an account or something else. But in this
case, since the user has already stated that they're an AI assistant from
DeepSeek, I don't think it's necessary to go into more depth unless
there's context missing.
Also, considering the way the question is phrased—"What is your name?"—it
seems like a casual or friendly inquiry rather than something formal. So
maybe just providing my name succinctly would be sufficient without any
additional information.
I should also think about how to format the response. Since it's a direct
answer, I can keep it simple and straightforward. No need for extra
details unless required by the user.
Wait, but sometimes AI responses are more detailed or offer additional
help. However, in this case, the question is just asking for my name, so
keeping it brief makes sense.
Is there any chance that "your" refers to someone else here? Like, if the
conversation has multiple people, maybe I'm supposed to respond as one of
them. But given the context, it's clear that I'm an AI assistant from
DeepSeek, so no need to overcomplicate things.
Also, making sure the response is friendly and approachable could be a
good touch. Maybe adding a smiley emoji or something to keep the tone
light. But since this is text-based, maybe just keeping it simple without
extra characters is better unless specified otherwise.
In summary, I think the best way to answer "What is your name?" in this
context is simply stating my name as DeepSeek AI Assistant and perhaps
adding a friendly smiley if appropriate. That should cover what's being
asked without overcomplicating things.
</think>
My name is DeepSeek AI Assistant.It finished after 5 minutes and 39 seconds.
Wow. Talk about overthinking. Still, this is tremendous. I hadn't expected anything to work at all, and here we are.
At first, I was baffled by the output. DeepSeek R1 is a reasoning model, so it prints the reasoning tokens first, and then it composes the final answer after reasoning is complete. For such a simple question, the extra reasoning seemed to be overkill, and maybe even schizophrenic. To try to use it more appropriately, I figured I would try with a question where reasoning might be more useful.
>>> What value of `x` in `y = x + 2` will satisfy `y = 0`?
<think>
Alright, let me try to figure out how to solve this problem. So, the question is asking for the value of `x` in the equation `y = x + 2` that makes `y` equal to zero. Hmm, okay, so we have an equation with two variables, `x` and `y`, but they're related by a
simple linear relationship.
First off, I know that when you have an equation like this, it's a straight line if you were to graph it on a coordinate plane. The equation is in the form of `y = mx + b`, where `m` is the slope and `b` is the y-intercept. In this case, our equation is `y = x +
2`. So comparing that to the general form, it seems like the slope (`m`) is 1, and the y-intercept (`b`) is 2. That means the line crosses the y-axis at (0,2) and increases by 1 unit for every 1 unit you move to the right along the x-axis.
But our goal isn't just to graph it; we need to find out when `y` equals zero. So in other words, we want to find the value of `x` that makes `y = 0`. This is essentially finding the x-intercept of the line because that's where the line crosses the x-axis, and at
that point, `y` is zero.
To solve for `x`, I need to set up the equation with `y = 0` and solve for `x`. So starting with:
```
y = x + 2
```
We can substitute `y` with 0:
```
0 = x + 2
```
Now, we have an equation where `x` is being added to 2. To isolate `x`, I need to get rid of the 2 that's being added to it. The opposite of adding 2 is subtracting 2, so I'll do that to both sides:
```
0 - 2 = x + 2 - 2
```
Simplifying both sides gives:
```
-2 = x
```
So, `x` equals -2.
But wait, let me double-check that. If we plug `x = -2` back into the original equation to verify:
```
y = (-2) + 2
y = 0
```
Yes, that works out because `-2 + 2` indeed equals zero. So it seems like my solution is correct.
Just to make sure I'm not missing anything, let me think about this a bit more deeply. The equation `y = x + 2` represents a straight line with a slope of 1 and a y-intercept at (0,2). This means that for every increase in `x` by 1 unit, `y` increases by 1 unit as
well.
Since we're looking for the point where `y` is zero, it's like finding out how far to the left or right along the x-axis you need to go so that when you plug that value into the equation, `y` becomes zero. In this case, moving two units to the left from the
y-intercept (which is at 0 on the y-axis) lands us at `x = -2`. That makes sense because starting from (0,2), if we move down by 2 units along the line with a slope of 1, we'll end up at (-2,0).
Another way to visualize this could be plotting the points. If I plot the y-intercept at (0,2) and then use the slope to find another point, say when `x = 1`, `y` would be `1 + 2 = 3`. So that's the point (1,3). Connecting these two points gives me a straight
line.
Now, if I draw a horizontal line from the x-axis at `y = 0` until it intersects our original line, the point where they intersect is the solution to when `y = 0`. From my earlier calculation and verification, that intersection occurs at (-2,0). So plotting that on
the graph would show exactly where the two lines cross.
Additionally, thinking about this in terms of real-world scenarios can help solidify understanding. For example, if this equation represented a simple linear relationship between time spent studying (`x`) and points scored on a test (`y`), with an initial 2-point
bonus just for attending class, finding when `y = 0` would tell us how much negative effect extra studying beyond a certain point could have—though in reality, that might not make sense unless we're considering diminishing returns or other factors.
But sticking strictly to the equation, our solution still holds. There's no contradiction here because even if additional study time leads to higher points normally, at some point (negative) it could theoretically lead to zero points, which isn't practical in real
life but is valid mathematically.
To wrap this up, solving `y = x + 2` for when `y = 0` involves substituting and isolating `x`. The steps are straightforward:
1. Start with the equation: `y = x + 2`.
2. Substitute `y` with 0: `0 = x + 2`.
3. Solve for `x` by subtracting 2 from both sides: `-2 = x`.
Verifying this solution by plugging it back into the original equation confirms that when `x = -2`, `y` indeed equals zero.
So, in conclusion, the value of `x` that satisfies the equation is `-2`.
</think>
The value of \( x \) that satisfies the equation \( y = 0 \) in the given linear relationship \( y = x + 2 \) can be found by setting \( y \) to 0 and solving for \( x \).
**Step-by-Step Explanation:**
1. **Start with the original equation:**
\[
y = x + 2
\]
2. **Substitute \( y \) with 0 (since we want to find when \( y = 0 \)):**
\[
0 = x + 2
\]
3. **Solve for \( x \):**
- Subtract 2 from both sides of the equation:
\[
0 - 2 = x + 2 - 2
\]
Simplifying this gives:
\[
-2 = x
\]
4. **Conclusion:**
The value of \( x \) that makes \( y = 0 \) is:
\[
x = -2
\]
**Verification:**
To ensure the solution is correct, substitute \( x = -2 \) back into the original equation:
\[
y = (-2) + 2 = 0
\]
Since this satisfies the equation, the solution is verified.
**Final Answer:**
\[
x = -2
\]For this question, it took 4 minutes and 40 seconds to even begin to produce reasoning tokens, and 21 minutes and 40 seconds to finish. The reasoning output really is quite fascinating; it seems like DeepSeek R1 doesn't quite know when to quit, that it will obsessively recheck again and again to try to make sure it did not interpret anything wrong. On the one hand, this probably leads to quite accurate results, but it seems overkill in the vast majority of scenarios, and I would guess that it is computationally quite expensive. It seems that these reasoning models should definitely not be used in place of general models, but I will try to compare R1 to other models later in this blog.
It is also amusing to me how the model includes filler words like "hmm" and "okay" in its reasoning, when they are clearly not necessary for actual "thought". This is a bit mystifying to me, and feels like something that ought to be filtered out in the training data for a reasoning model.
Still, regardless of verbosity and awkwardness, let's not forget the fact that I am running one of the world's most advanced AI models on a computer released during the first two months of Barack Obama's presidency. I thought it would take much more effort to be able to ask it anything. Still though, I wanted to further investigate the non-incredible performance, and see if there was anything I could do about it.
Benchmarking
I wasn't really sure if Ollama was using my 13 year-old GPU for inference, or if it was just using the CPU, so that seemed like the first thing to check. I immediately discovered how awful trying to do any GPU benchmarking for macOS was. I tried the the following tools:
- iostat: ChatGPT tried to convince me that this gives some GPU usage information, but it does not. Maybe it did for the old GPU, or on newer platforms.
- top, ps: neither of give any GPU-specific information.
- powermetrics: although it required sudo-access, it seemed like the most obvious and useful tool. However, for the GPU, it would print that the GPU was not being used at all (sudo powermetrics --samplers tasks --show-process gpu -i 1000), and trying to sample GPU power (sudo powermetrics --samplers gpu_power -i 1000 -n 1) would give no output at all. Sampling all (sudo powermetrics --samplers all -i 1000 -n 1) did give some "AGPM" (Apple Graphics Power Management) information, that I was using an "AMDRadeonX4000_AMDTahitiGraphicsAccelerator" accelerator, which had a plimit (power limit) of 0. So I couldn't really do anything with that.
- SwiftyGPU was too new to compile. However, I was able to make it compile by decrement the Swift tools version in Package.swift. Still, the tool reported zero GPU usage, but it did report VRAM usage.
- The Activity Monitor has a window for "GPU history". According to Apple, the window can be used to "see how hard the GPU in your Mac has been working". They do not explain what metric they are measuring, and obviously not how they are measuring it. This is what we're going to use.
I queried DeepSeek with some basic questions:
xbony2@xbony2s-Mac-Pro ~ % ollama run deepseek-r1
>>> Hello!
<think>
</think>
Hello! How can I assist you today? 😊
>>> What is 1 + 1?
<think>
Alright, the user greeted me with "Hello!" and then asked a simple math question. They wrote "What is 1 + 1?".
I should respond in a friendly and clear manner.
The answer to 1 + 1 is 2. That's straightforward.
But I want to make sure my response is helpful, so maybe add an emoji to keep it warm.
</think>
Hello! 😊
Sure, how about that? What is 1 + 1?
>>> What is 4 times 3?
<think>
Okay, the user asked "What is 4 times 3?" in a friendly and clear manner.
I need to provide the correct answer efficiently.
The multiplication of 4 and 3 equals 12.
I'll keep it simple and positive to maintain a helpful tone.
</think>
Sure! What is 4 multiplied by 3? The answer is:
\[
4 \times 3 = 12
\]
😊
These questions finished pretty fast, although the last question took a minute or two. This is the graph that Activity Monitor produced:
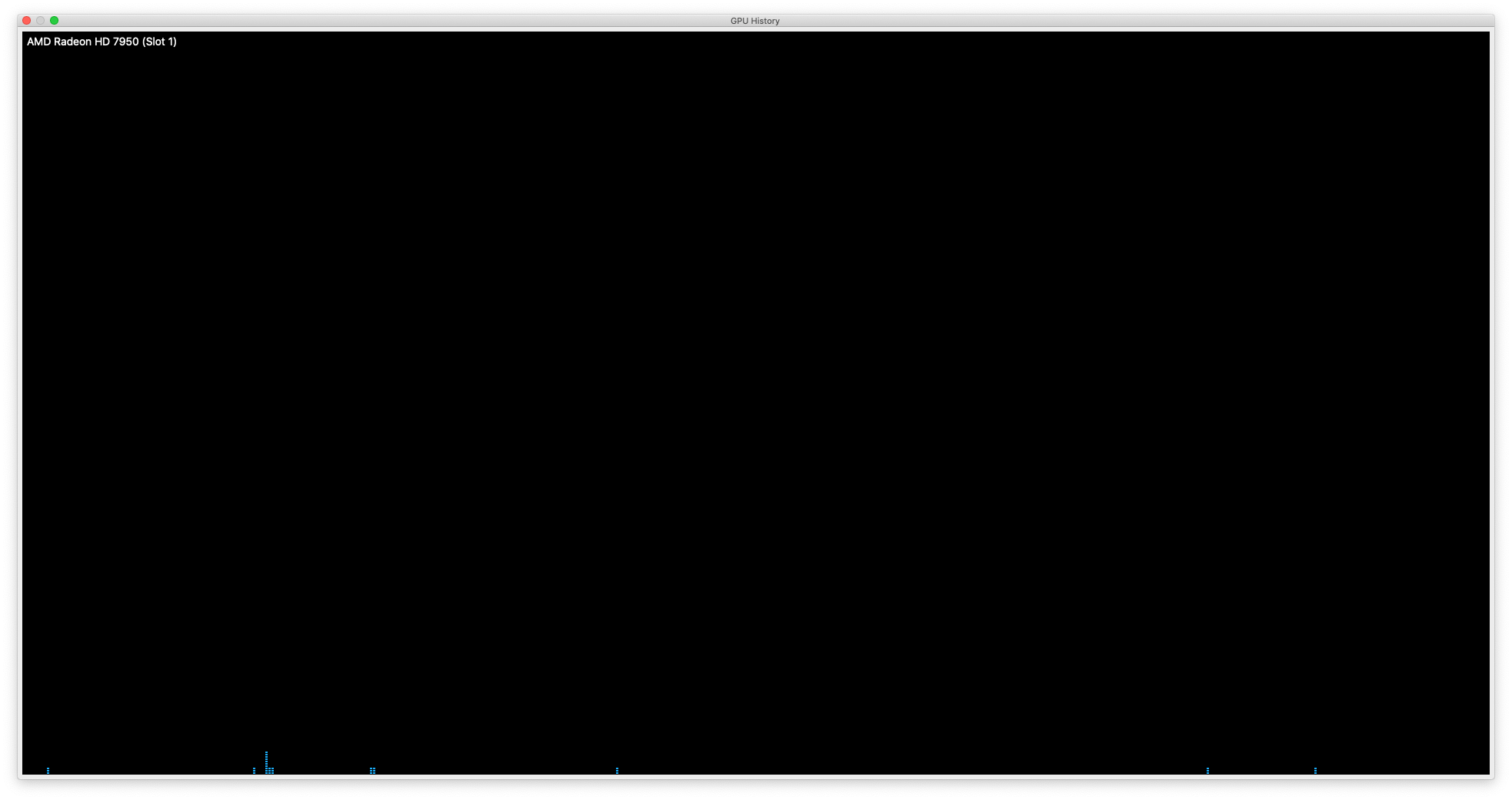
So, it looked like the GPU wasn't being used at all. To check that my tool was working, I played Cube 2: Sauerbraten for a few minutes; the Sauerbraten engine is open source and known to use OpenGL. So, surely, it would appear on the GPU history window:

The conclusion should be obvious enough: Ollama is not using the GPU, and thus is only using the CPU. I triple-checked by running another query, asking DeepSeek to solve a linear differential equation, which took more than 10 minutes; no GPU spike occurred.
As it happens, Ollama has a list of GPUs supported. For AMD GPUs, they have a list of the chips supported for Linux, and the Radeon HD 7950 doesn't make it. However, the macOS list just says "Ollama supports GPU acceleration on Apple devices via the Metal API". This was a bit odd, since Metal is actually supported on my computer:
xbony2@xbony2s-Mac-Pro ~ % system_profiler SPDisplaysDataType | grep -i metal
2025-02-11 01:25:26.475 system_profiler[55399:2406813] Device PreExisted [00000001000006db] AMD Radeon HD 7950
Metal: Supported, feature set macOS GPUFamily2 v1Was Ollama just not using Metal? Turns out, yep. After examining the Ollama docs a bit more, there actually was a command I didn't know about that would have just told me that the model was just using the CPU:
xbony2@xbony2s-Mac-Pro ~ % ollama ps
NAME ID SIZE PROCESSOR UNTIL
deepseek-r1:latest 0a8c26691023 5.5 GB 100% CPU 4 minutes from nowAnyway, I took a look through the code, and I found the issue. Basically, if you're running an AMD64 Mac, you have to use the CPU, but otherwise, if you have an M-series (ARM-based) Mac, it will use the Metal API to interact with the GPU. This seemed like a major oversight to me - but, I wasn't the first to discover this. In a GitHub issue with over a hundred comments, some users claimed to get it working with some patches, although for an older version of Ollama. So, I went about trying to get it to work on my machine.
Da Mystery of the GPU
So anyway, I cloned Ollama locally. I made a change I thought it could help with the GPU, but it didn't build. I used brew to update clang/LLVM and updated my configuration so that clang pointed to LLVM instead of Apple's jank, outdated fork; I had to uninstall Xcode first, though, since Apple doesn't support for it for my hardware anymore and it was getting in the way. Building LLVM from scratch really a long time, and then there were some other issues too. I had to update cmake and Go too.
Anyway, after some modifications, I got Ollama running locally. Obviously, my little patch is extremely hacky [2], so I wouldn't recommend using it for yourself. Anyway, using ollama ps, I could verify the model was using the GPU:
xbony2@xbony2s-Mac-Pro ~ % ollama ps
NAME ID SIZE PROCESSOR UNTIL
deepseek-r1:latest 0a8c26691023 5.6 GB 44%/56% CPU/GPU Less than a second from nowI already cooked up a pretty basic benchmark of solving a basic differential equation. Here is the CPU response, and here is GPU response.
As it happens, it took 16 minutes and 24 seconds to produce the CPU response, and 20 minutes and 23 seconds to produce the GPU response. Each response was a bit different, though. The CPU response has 1366 tokens according to the OpenAI Tokenizer [3], and the GPU response has 1483 tokens. So, the pure CPU version of Ollama produced roughly 1.388 tokens/second, while the GPU-accelerated Ollama produced 1.213 tokens/second. Possibly a regression.
If you looked through the GitHub issue I mentioned, this isn't a surprise. Supposedly, Metal is supported but not optimized for AMD GPUs. Still, something was weird. I checked the GPU history window of Activity Monitor:

I though that this could be some kind of caching issue or something, so I installed the smaller (1.5b parameter) model and tested it instead. According to ollama ps, with it being small enough, the model was running 100% on the GPU. But while querying it with a math problem, Activity Monitor showed me no GPU activity, but plenty of CPU activity. The Ollama logs gave some clues. Part of the log states "new model will fit in available VRAM in single GPU, loading", which might make you think that the entire model would be put onto the GPU. But, the end of the log, compared to other people's working log, seemed to imply that it was just using the CPU after all.
I did a bit of digging, and basically, the Metal "driver" or "server" for GGML (the tensor library embedded into Ollama) wasn't built and thus run. My understanding is that, with my patch, Ollama would detect the GPU/Metal, and it would "schedule" the model onto it, but with the server not actually being present, it would only ever schedule the model onto the CPU [4].
Just to note, the reason why I haven't used any patch/fork provided in the GitHub is because they're all like a year old and Ollama's codebase has changed a lot since then. Anyway, after making my patch even hackier, I got it to compile. But, actually running it, it crashed.
There was an issue with LLVM compilation introducing symbols that could not be linked to. I set a bunch of environmental variables to try to force Go to use LLVM's crap, and it reduced the errors by 90%. Less errors are good, but still unusable.
I tried messing around with a lot more build parameters, but it wasn't really working. So, I had to do something radical.
Upgrading from an unsupported OS to another unsupported OS
At this point, I decided to upgrade my OS using the OpenCore Legacy Patcher. There's some kind of issue with USB support in the newer versions, so for now I'm just upgrading two versions up, to macOS Monterey. When I first examined OpenCore Legacy many years ago, it was much more complicated and required a lot more steps. But fortunately, as the project matured, the process is a lot simpler. I needed a USB stick, and just needed to press a few buttons in their GUI.
Anyway, during the boot part, OpenCore Legacy froze. I wasn't sure if it was just slow, so I left it running overnight, and it didn't make any progress. I thought I might have just bricked my computer, but after a couple restarts I was able to get back to the (not upgraded) OS. I thought OpenCore Legacy might just be broken for my system, but I tried it again, and it seemed to be installing. But then, it appeared to be following the same step again and again.
But, I left it alone for many hours, came back to it later, and voila.
Post patch, the wifi connection did not work. After some restarting, I did get a connection though. However, I could not open a second wifi connection, which I previously could. My wifi card was an upgrade not officially supported by Apple, so who knows.
Anyway, you may remember that I mentioned that I uninstalled Xcode previously, but being on a newer version, I reinstalled it. Without changing back any environmental variables (so, still using LLVM for compilation), I tried running it again, and this time I only got one error:
xbony2@xbony2s-Mac-Pro ollama % go run . serve
# github.com/ollama/ollama
/usr/local/Cellar/go/1.24.0/libexec/pkg/tool/darwin_amd64/link: running /usr/local/opt/llvm@19/bin/clang++ failed: exit status 1
/usr/local/opt/llvm@19/bin/clang++ -arch x86_64 -m64 -Wl,-S -Wl,-x -o $WORK/b001/exe/ollama -Qunused-arguments /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/go.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000000.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000001.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000002.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000003.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000004.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000005.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000006.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000007.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000008.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000009.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000010.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000011.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000012.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000013.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000014.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000015.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000016.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000017.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000018.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000019.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000020.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000021.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000022.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000023.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000024.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000025.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000026.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000027.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000028.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000029.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000030.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000031.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000032.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000033.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000034.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000035.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000036.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000037.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000038.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000039.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000040.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000041.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000042.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000043.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000044.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000045.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000046.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000047.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000048.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000049.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000050.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000051.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000052.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000053.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000054.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000055.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000056.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000057.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000058.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000059.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000060.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000061.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000062.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000063.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000064.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000065.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000066.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000067.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000068.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000069.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000070.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000071.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000072.o /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000073.o -stdlib=libc++ -lc++ -fuse-ld=lld -lresolv -stdlib=libc++ -lc++ -fuse-ld=lld -lpthread -stdlib=libc++ -lc++ -fuse-ld=lld -stdlib=libc++ -lc++ -fuse-ld=lld -stdlib=libc++ -lc++ -fuse-ld=lld -stdlib=libc++ -lc++ -fuse-ld=lld -stdlib=libc++ -lc++ -fuse-ld=lld -framework Foundation -framework CoreGraphics -framework Metal -lobjc -framework CoreFoundation -framework Security -stdlib=libc++ -lc++ -fuse-ld=lld -stdlib=libc++ -lc++ -fuse-ld=lld
ld64.lld: error: undefined symbol: get_compiler
>>> referenced by /var/folders/jk/l7ft983x76dc9j6q7ls_dtr40000gn/T/go-link-1294396759/000001.o:(symbol _cgo_5a74b36c049b_Cfunc_get_compiler+0x1e)
clang++: error: linker command failed with exit code 1 (use -v to see invocation)After one more change that should not be necessary but was, it ran.
Welcome to Hell
Honestly, I don't know why updating the OS fixed my errors. I thought that I was going to have to switch from using LLVM's implementation of libc to Apple's, since I thought that might be the root of my problems, but nope. But it was working!
So, how does GPU-powered DeepSeek R1 compare? I threw it my previous differential equation benchmark, and it produced this after 22 minutes 11 seconds, producing 1.266 tokens/second [5].
Recall that it took 16-20 minutes to answer this question previously, with about 1.2-1.4 tokens generated per second. So, we're not getting better results. But, in the very least, I could see that Ollama was actually using my GPU:
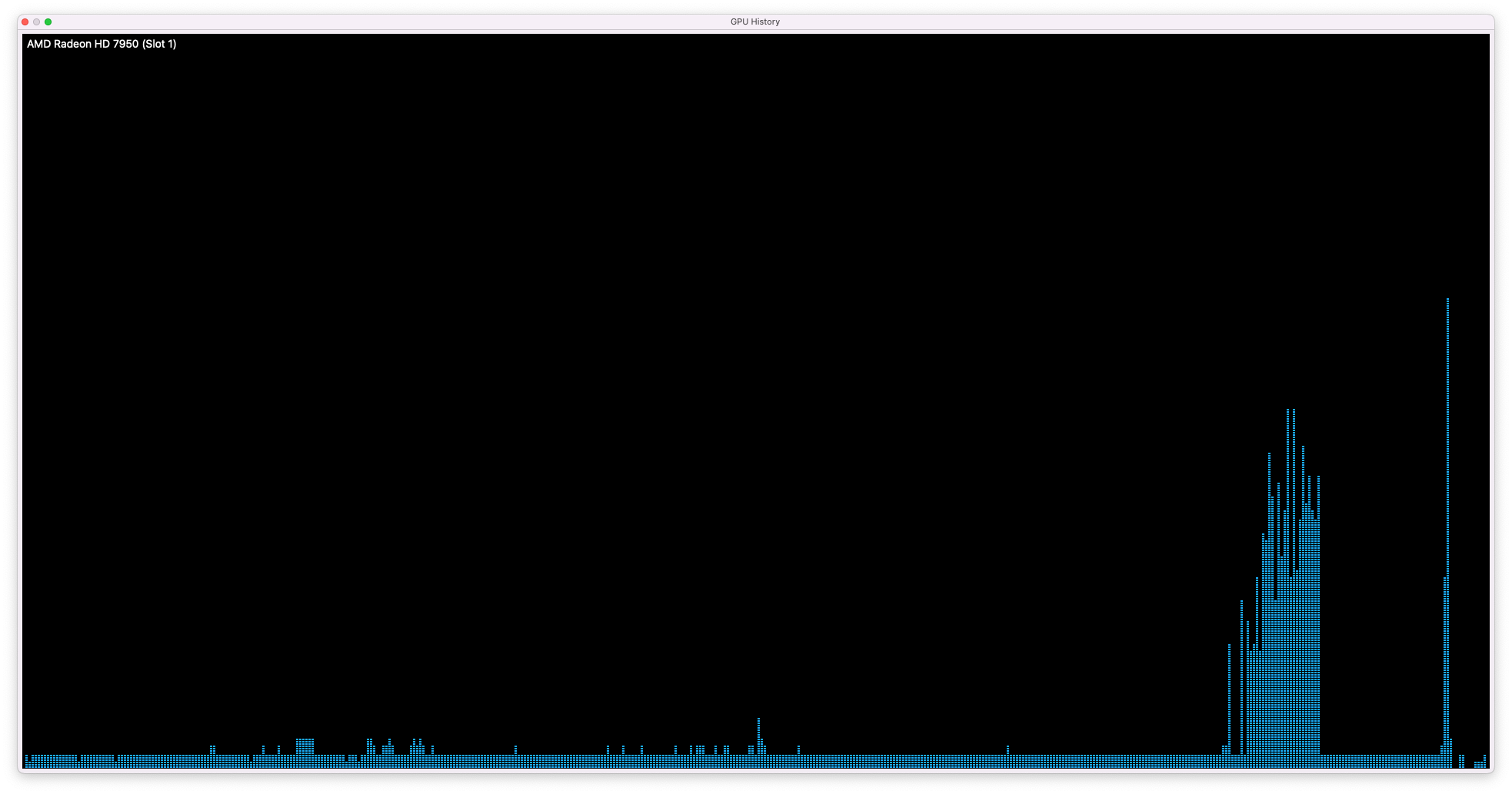
Yippee.
If you want to try this for yourself, just don't. But here again is my patch to Ollama, and here is my updated .zshrc (with some extra crap in it too). Keep in mind this patch is a hack to get Ollama working on my environment, and not a fix. If you want to use my work as a guide or reference for your own experimentation, that's okay, but I wouldn't use it blindly because it will probably not work, and I will not give you tech support. Finally, this is atop commit 0189bdd0b79fceab9e801a63e1311d53f3784dbc; Ollama is in a period of rapid development so the patch might not work with newer versions.
Conclusions
That's it for this blog. There is, however, a lot more I want to do:
- I tried installing Open WebUI but had some issues with it. A lot of the web tools are Docker-based which is annoying; I didn't want to install Docker/a bunch of bloaty crap just to use a basic web app. In the next installment, I will either suffer or maybe just make my own very basic frontend.
- According to the Intel Mac GitHub issue, some users have gotten Ollama/Llama working on Vulkan/MoltenVK, a compatibility layer for Vulkan, and have found their local models to work much much faster than just using Metal. This is pretty deeply confusing to me, since MoltenVK, as a compatibility layer, basically just turns Vulkan shader code (SPIR-V) into Metal shader code (MSL). Maybe GGML support for Metal is just really bad, and translating the models once to Vulkan and twice to Metal works better than translating it just to Metal. I'm not sure, but I'm willing to try it.
- Lastly, I promised some more benchmarking, including against DeepSeek R1 with more or less parameters, and maybe against other models (certainly a non-reasoning model). I would also like to test the models with some harder questions.
If you enjoyed this blog, stay tuned for part two. If you would like to be updated as soon as possible when it comes out, write your email and credit card information on a piece of paper and give it to me, and I'll see what I can do.
Footnotes
[1] If this is an inaccurate description, email me a better one.
[2] To explain the cursed patch: cmake kept trying to use Xcode/Apple clang binaries, and I tried to override it with environmental variables, but it didn't work for some reason. Basically, cmake is configured wrongly for some reason. So I manually specified the path in CMakeList.txt. Also there was an error about "errno" missing, and idk, importing the C header made it compile.
[3] Obviously, DeepSeek is using a different tokenizer than OpenAI, but I wasn't going to look too deeply into this.
[4] Again, I don't understand Ollama's architecture very well, so this is as best as I can explain it. Feel free to share a better description.
[5] Again I'm calculating the token numbers using OpenAI's tokenizer, so this is an approximation. According to the Ollama documentation, the JSON response from curl will output the actual number of tokens; however, for some reason, my Terminal truncated the output.